Хакеры ищут разные пути взлома ваших сайтов. В большистве случаев, если только сайт не представляет какой то коммерческой ценности, это резвятся детишки, пытаясь сомоутвердиться.
На днях сайты моего хостинга, мягко говоря, — «прилегли». Было видно, что DOS-ят какой то из сайтов.
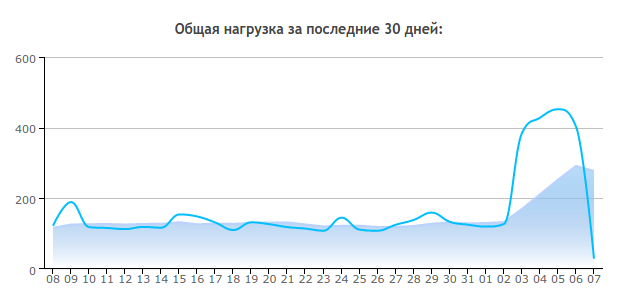
А видно это прежде всего из статистики использования ресурсов сервера:
Я удивился по той причине, что каких либо коммерческих ресурсов на хостинге не лежит. Чего, спрашивается, DOS-ить то? С какой целью?
Что видно на диаграмме?
На первой картинке мы наблюдаем загрузку процессора. Она измеряется в 100% на одно ядро. Где то 15.00 по гринвичу атака началась, а в районе 21.00 я попросил провайдера что то с этим сделать. Тех поддрежка начала перенос хостинга на другой мастер-сервер. Видимо, чтобы дать мне возможность использовать больше системных ресурсов. Часов в 22:00 начался переезд, проверка целостности файлов и другие процедуры.
Не хотелось на самом деле даже возиться — и я просто лег спать, ибо, «утро вечера мудренее».
Что видно в логах сервера?
Статистика на утро уже не показывала каких либо аномалий. Сайты все равно открывались через раз и далеко не сразу, т.е. атака продолжалась. То ли статистика писалась все ещё со старого сервера, то ли это уже были данные мастер-сервера…
Поэтому я перешел к изучению логов, чтобы выяснить куда «стучат».

Когда я поглядел в логи, стало ясно, что можно не беспокоиться — стучит какая то школота с одного и того же ip адреса в /xmlrpc.php одного из моих сайтов на WordPress. Скорее всего занимается брут-форсом админского пароля.
Приятного конечно же мало, так как «лежат» и все остальные сайты виртуального сервера. И самое досадное, что я не использую эти XML сервисы ни на одном из своих WP сайтов.
Блокируем XML RPC.
Самое простое, что вы можете сделать в данной ситуации — удалить из корневой папки сайта файл /xmlrpc.php . Сервер не найдя скрипа, не будет запускать PHP, тратить ресурсы памяти и время процессора. Решение простое, но не красивое. Во-первых, кто то может пользоваться возможностями RPC. К примеру, публиковать записи на сайт через один из многих Weblog клиентов. А во-вторых, файл будет восстановлен после очередного обновления WP.
Если ваш сервер работает на Apache, то можно блокировать доступ к xmlrpc.php , не удаляя самого файла. Нужно добавить следующие инструкции в начало вашего .htaccess файла в корневой директории сайта на WordPress. Это заблокирует доступ к файлу с любых адресов.
# XML-RPC DDoS PROTECTION
# XML-RPC DDoS PROTECTION < FilesMatch "^(xmlrpc\.php)" > Order Deny , Allow Deny from all < / FilesMatch > |
В моем случае можно было заблокировать только IP-адрес источника запросов, т.к. использовался один и тот же адрес. Для блокировки только IP адреса «школодосера»:
< FilesMatch "^(xmlrpc\.php)" > Order Allow , Deny Deny from 85.93.93.157 Allow from All < / FilesMatch > |
Но если вы пользуетесь RPC, то можно составить белый список адресов, которые имеют доступ к скрипту xmlrpc.php.
Несколько дней назад я заметил, что нагрузка моих сайтов на хостинг выросла в разы. Если обычно она составляла в районе 100-120 "попугаев" (CP), то за последние несколько дней она возросла до 400-500 CP. Ничего хорошего в этом нет, ведь хостер может перевести на более дорогой тариф, а то и вовсе прикрыть доступ к сайтам, поэтому я начал разбираться.
Но я выбрал метод, который позволит сохранить функциональность XML-RPC: установку плагина Disable XML-RPC Pingback . Он удаляет лишь "опасные" методы pingback.ping и pingback.extensions.getPingbacks, оставляя функционал XML-RPC. После установки плагин нужно всего лишь активировать - дальнейшая настройка не требуется.
Попутно я забил все IP атакующих в файл.htaccess своих сайтов, чтобы заблокировать им доступ. Просто дописал в конец файла:
Order Allow,Deny Allow from all Deny from 5.196.5.116 37.59.120.214 92.222.35.159
Вот и все, теперь мы надежно защитили блог от дальнейших атак с использованием xmlrpc.php. Наши сайты перестали грузить хостинг запросами, а также атаковать при помощи DDoS сторонние сайты.
Введение в XML-RPC
В Сети существует много разных ресурсов, которые предоставляют пользователям определенную информацию. Имеются в виду не обычные статические страницы, а, к примеру, данные, извлекаемые из базы данных или архивов. Это может быть архив финансовых данных (курсы валют, данные котировок ценных бумаг), данные о погоде, или же более объемная информация - новости, статьи, сообщения из форумов. Такая информация может представляться посетителю страницы, к примеру, через форму, как ответ на запрос, или же каждый раз генерироваться динамически. Но трудность в том, что часто такая информация нужна не столько конечному пользователю - человеку, сколько другим системам, программам, которые эти данные будут использовать для своих расчетов или других потребностей.
Реальный пример: страница банковского сайта, на которой показываются котировки валют. Если вы заходите на страницу как обычный пользователь, через браузер, вы видите все оформление страницы, баннеры, меню и другую информацию, которая "обрамляет" истинную цель поиска - котировки валют. Если вам надо вносить эти котировки в свой интернет-магазин, то ничего другого не останется, как только вручную выделить нужные данные и через буфер обмена перенести на свой сайт. И так придется делать каждый день. Неужели нет выхода?
Если решать проблему "в лоб", то сразу напрашивается решение: программа (скрипт на сайте), которой надо данные, получает страницу от сервера как "обычный пользователь", разбирает (парсит) полученный html-код и выделяет из него нужную информацию. Это можно сделать или обычным регулярным выражением, или при помощи любого html-парсера. Сложность подхода - в его неэфективности. Во-первых, для получения небольшой порции данных (данные о валютах - это буквально десяток-другой символов) надо получать всю страницу, а это не менее нескольких десятков килобайт. Во-вторых, при любом изменении кода страницы, к примеру, дизайн поменялся или что-то еще, наш алгоритм разбора придется переделывать. Да и ресурсов это будет отбирать порядочно.
Поэтому разработчики пришли к решению - надо разработать какой-то универсальный механизм, который бы позволил прозрачно (на уровне протокола и среды передачи) и легко обмениваться данными между программами, которые могут находиться где угодно, быть написанными на любом языке и работать под управлением любой операционной системы и на любой аппаратной платформе. Такой механизм называют сейчас громкими терминами "Веб-сервисы" (web-service), "SOAP", "архитектура, ориентированная на сервисы" (service-oriented architecture). Для обмена данными используются открытые и проверенные временем стандарты - для передачи сообщений протокол HTTP (хотя можно использовать и другие протоколы - SMTP к примеру). Сами данные (в нашем примере - курсы валют) передаются упакованными в кросс-платформенный формат - в виде XML-документов. Для этого придуман специальный стандарт - SOAP.
Да, сейчас веб-сервисы, SOAP и XML у всех на слуху, их начинают активно внедрять и крупные корпорации вроде IBM и Microsoft выпускают новые продукты, призванные помочь тотальному внедрению веб-сервисов.
Но! Для нашего примера с курсами валют, которые должны передаваться с сайта банка в движок интернет-магазина такое решение будет очень сложным. Ведь только описание стандарта SOAP занимает неприличные полторы тысячи страниц, и это еще не все. Для практического использования придется изучить еще работу со сторонними библиотеками и расширениями (только начиная с PHP 5.0 в него входит библиотека для работы с SOAP), написать сотни и тысячи строк своего кода. И все это для получения нескольких букв и цифр - явно очень тяжеловесно и нерационально.
Потому существует еще один, с натяжкой можно сказать альтернативный стандарт на обмен информацией - XML-RPC. Он был разработан при участии Microsoft компанией UserLand Software Inc и предназначен для унифицированной передачи данных между приложениями через Интернет. Он может заменить SOAP при построении простых сервисов, где не надо все "корпоративные" возможности настоящих веб-сервисов.
Что же означает аббревиатура XML-RPC? RPC расшифровывается как Remote Procedure Call - удаленный вызов процедур. Это значит, что приложение (неважно, скрипт на сервере или обычное приложение на клиентском компьютере) может прозрачно использовать метод, который физически реализован и исполняется на другом компьютере. XML тут применяется для обеспечения универсального формата описания передаваемых данных. Как транспорт, для передачи сообщений применяется протокол HTTP, что позволяет беспрепятственно обмениваться данными через любые сетевые устройства - маршрутизаторы, фаерволы, прокси-сервера.
И так, для использования надо иметь: сервер XML-RPC, который предоставляет один или несколько методов, клиент XML-RPC, который может формировать корректный запрос и обрабатывать ответ сервера, а также знать необходимые для успешной работы параметры сервера - адрес, название метода и передаваемые параметры.
Вся работа с XML-RPC происходит в режиме "запрос-ответ", в этом и есть одно из отличий технологии от стандарта SOAP, где есть и понятия транзакций, и возможность делать отложенные вызовы (когда сервер сохраняет запрос и отвечает на него в определенное время в будущем). Эти дополнительные возможности больше пригодятся для мощных корпоративных сервисов, они значительно усложняют разработку и поддержку серверов, и ставят дополнительные требования к разработчикам клиентских решений.
Процедура работы с XML-RPC начинается с формирования запроса. Типичный запрос выглядит так:
POST /RPC2 HTTP/1.0
User-Agent: eshop-test/1.1.1 (FreeBSD)
Host: server.localnet.com
Content-Type: text/xml
Content-length: 172
В первых строках формируется стандартный заголовок HTTP запроса POST. К обязательным параметрам относятся host, тип данных (MIME-тип), который должен быть text/xml, а также длина сообщения. Также в стандарте указывается, что поле User-Agent должно быть заполнено, но может содержать произвольное значение.
Далее идет обычный заголовок XML-документа. Корневой элемент запроса -
Строка
Далее задаются передаваемые параметры. Для этого служит секция
После описания всех параметров следуют закрывающие теги. Запрос и ответ в XML-RPC это обычные документы XML, поэтому все теги обязательно должны быть закрыты. А вот одиночных тегов в XML-RPC нет, хотя в стандарте XML они присутствуют.
Tеперь разберем ответ сервера. Заголовок HTTP ответа обычный, если запрос успешно обработан, то сервер возвращает ответ HTTP/1.1 200 OK. Также как в запросе, следует корректно указать MIME-тип, длину сообщения и дату формирования ответа.
Само тело ответа следующее:
Теперь вместо корневого тега
Если при обработке вашего запроса произошла ошибка, то вместо В
ответе будет элемент
А теперь рассмотрим кратко типы данных в XML-RPC. Всего типов данных есть 9 - семь простых типов и 2 сложных. Каждый тип описывается своим тегом или набором тегов (для сложных типов).
Простые типы:
Целые числа
- тег
Логический тип
- тег
ASCII-строка
- описывается тегом
Числа с плавающей точкой
- тег
Дата и время
- описывается тегом
Последним простым типом является строка, закодированная в base64
,
которая описывается тегом
Сложные типы представлены структурами и массивами. Структура определяется
корневым элементом
Массивы не имеют названий и описываются тегом
Конечно, кто-то скажет, что такой перечень типов данных очень беден и "не позволяет развернуться". Да, если надо передавать сложные объекты, или большие объемы данных, то лучше использовать SOAP. А для небольших, нетребовательных приложений вполне подходит и XML-RPC, более того, очень часто даже его возможностей оказывается слишком много! Если учесть легкость развертывания, очень большое количество библиотек для почти любых языков и платформ, широкую поддержку в PHP, то XML-RPC часто просто не имеет конкурентов. Хотя сразу советовать его в качестве универсального решения нельзя - в каждом конкретном случае надо решать по обстоятельствах.
Каждый у кого есть свой веб-сайт хочет повысить его безопасность, если нет, то хочет чтобы он был всегда в безопасности... Собственно в этой статье мы и разберем принципы и основы защиты движка WordPress, а конкретно мы посмотрим более детально на файл xmlrpc.php . Не забывайте делать бекапы при изменении или внесении тех или иных правок в файлы. Давайте начнем.
Уязвимость WordPress через файл xmlrpc.php, решение проблемы:
Поясню для незнающих или непонимающих цель данного файла. С его помощью можно управлять блогом на WordPress через различные приложения. Не знаю конечно как большинство, но лично я этим не пользуюсь и соответственно зачем мне оставлять лишний шанс взломать сайт, я его уберу... Ведь файл этот достаточно уязвимый. Однако помните, вы можете убрать его из использования, а потом всегда можете вернуть, если появится необходимость в нем.
Для начала отключим файл xmlrpc.php , через него проходит достаточно много атак на сайт, а это не есть хорошо. Как и обычно есть 2 варианта сделать это, первый внесением правок в файлы.htaccess и functions.php, а также header.php (наиболее правильный на мой взгляд способ). И методом установки плагина, но об этом чуть позже. Перейдем к правкам файлов.
В файл functions.php вставляем:
// отключаем xmlrpc.php add_filter("xmlrpc_enabled", "__return_false"); remove_action("wp_head", "rsd_link");
В файле header.php удаляем:
Кроме этого способа есть и так скажем автоматический, про который я говорил ранее. Суть его в том, что мы устанавливаем дополнительный плагин . Способ конечно хороший и достаточно простой, но я его не рекомендую использовать. Почему? Ну все просто, лишний плагин - лишняя нагрузка. Да и зачем ставить плагин туда, где грубо говоря добавив пару строк мы избавимся от ненужной нам функции и сделаем сайт производительнее и легче.
С полудня субботы на моем сервере, где хостится около 25 сайтов на Wordpress, начались дикие тормоза. Так как мне удалось пережить предыдущие атаки (атака 1 - ровно год назад , атака 2 - в марте) не замеченными, то я не сразу понял, в чем дело.
Когда разобрался, то выяснилось, что идет перебор паролей + множество запросов к XMLRPC.
В результате удалось это все отсечь, хотя и не сразу. По катом три простых приема, как этого избежать.
Эти приемы скорее всего всем известны, но я наступил на пару граблей, которых не нашел в описаниях - вдруг это кому-то сэкономит время.
1. Останавливаем перебор, плагин Limit Login Attempts - ставим именно его, так как другие защиты сильно подвешивают сервер, например, при использовании плагина Login Security Solution сервер умер через полчаса, плагин сильно грузит базу.
В настройке обязательно включите галочку «За прокси» - иначе он будет для всех определять ip вашего сервера и автоматически блокировать всех.
UPDATE, спасибо DarkByte , подробности ниже в комментах - галочку «За прокси» включаем только если не работает определение при включенном «Прямое подключение»
2. Отключаем XML-RPC - плагин Disable XML-RPC (его просто активировать и всё).
3. Закрываем wp-login.php - если обращаться к сайту через ip, то плагин не срабатывает и подборщики продолжают долбить сайт. Чтобы этого избежать, в.htaccess добавляем:
Файл wp-login копируем, переименовываем в любое странное имя, например poletnormalny.php и внутри файла автозаменой меняем все надписи wp-login.php на poletnormalny.php.
Все, теперь к админке можно обратиться только по вашему файлу.
После этих 3 несложных шагов сайты опять начали летать и пришло спокойствие.